How Talk to Bill Works
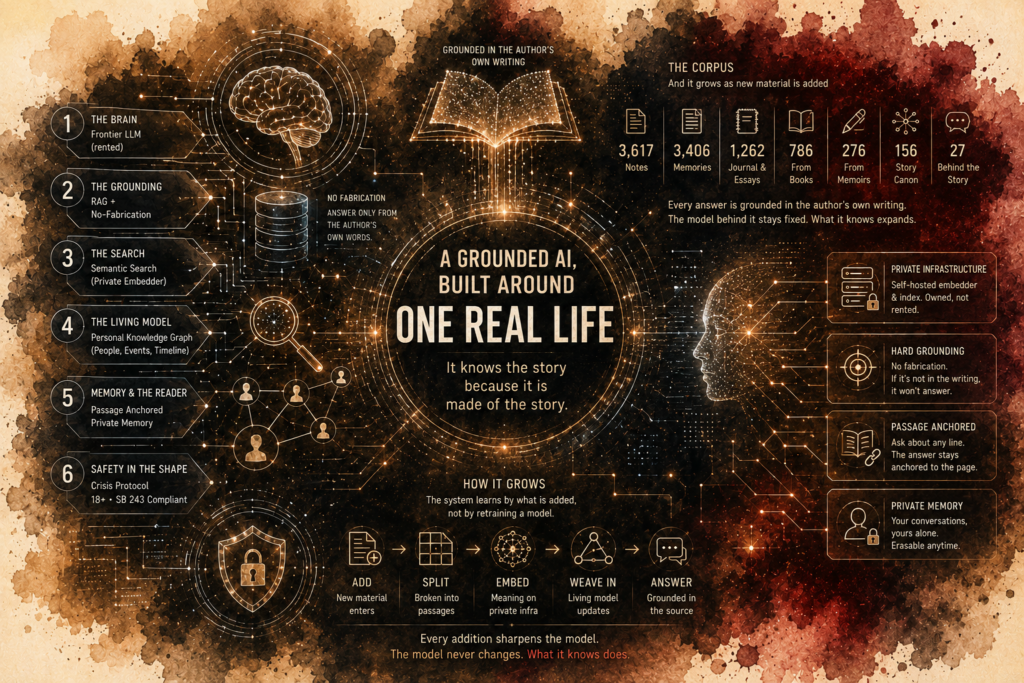
A grounded AI, built around one real life
Most current systems that attempt to speak for a real person tend to fail in one of two ways. Ask it something the person never wrote down and it answers anyway, improvising in their voice with total confidence, and getting it wrong. That is the default behavior of a large language model. It fills gaps. The opposite problem is just as bad: some systems can only repeat answers that were loaded in ahead of time, so the moment a reader asks something new, they have nothing to say. That is a recording, not a conversation. Neither one is a person a reader can actually know.
Talk to Bill is built as a third option, and the architecture is the whole point. Here is how it works.
Six layers, and the model never works alone
The brain
At the core is a frontier large language model, the same class of system behind the leading AI assistants, called over the internet. The model is rented. What matters is the architecture wrapped around it, because a raw model knows the world and almost nothing true about this author.
The grounding
The model answers from what the author actually wrote, not from its own training. Before it responds, the system retrieves the passages of the memoir, journals, and essays that bear on the question and hands them over with one rule: answer from these, and if they do not cover it, say so. When a reader highlights a line in the book and asks about that passage, the grounding tightens to its strictest form: answer only from the retrieved writing, and cite it. It also handles the hardest questions with care, so something that is true in feeling but not in literal fact is answered as felt truth and never asserted as fact. This is retrieval-augmented generation with a hard no-fabrication rule.
The search
Retrieval is primarily by meaning, with a keyword fallback so exact names and dates are never missed, and if the private embedder is ever offline the search falls back to keywords so answers never stop. Every passage in the corpus, about 5,700 of them, is converted into a vector embedding that captures what it means. That is semantic search. The embedding model runs on private, self-hosted infrastructure, so the component that reads and indexes the source material stays under the author's control.
The living model
Above flat retrieval sits a structured life-model: the people, the claims, the events, drawn across the whole life, each claim tied to the exact passage it came from so every answer can be traced back to its source. It powers the in-book reading experience and grows only as the author approves each entry by hand. Nothing surfaces until he approves it, so the map never guesses, it only sharpens as new material is added.
Memory and the reader
Signed-in readers get a private, growing memory. The author gently remembers who they are and picks up where they left off, and the reader can erase it, or download a copy of everything kept, in one tap. Inside the book, a reader can highlight any line and ask about that exact passage; the query is locked to the selected text, so the answer stays anchored to the page, and the system tells a self-help essay from a chapter of the novel and answers each in its own voice.
Safety in the shape
A crisis protocol, an adults-only policy stated up front (18+), and a clear AI disclosure line up with California's new companion-chatbot law, SB 243. The deeper safety is structural. Because the system is single-subject, grounded, refuses to fabricate, and speaks of real people by role rather than name, it sidesteps the open-ended roleplay the law was written to stop. After every answer, fixed filters strip AI verbal tells and swap the real family names for the names the book uses, so the voice and privacy rules hold even when the model slips. A hard daily spending ceiling and rate limits mean it can never be run away with, and when it reaches them it steps back with a kind word instead of an error.
The system learns by what is added, not by retraining a model
The model itself never changes. What grows is the corpus and the life-model. Each new memory, essay, or page runs through this pipeline and becomes part of what the system knows and how it answers. The result keeps becoming a closer model of the author over time, with no fabrication required.
And it grows as new material is added
Every answer is grounded in the author's own writing. These counts track the same index the system answers from, and they climb as each new memory, essay, or page is added. The model behind it stays fixed. What it knows expands.
This system against what is shipping now
The same capabilities, measured across the products this is most often compared to.
| This system | Amazon Ask This Book | Delphi | Personal.ai | Rebind | |
|---|---|---|---|---|---|
| Grounded only in the real person's own writing | ✓ | ~ | ✕ | ~ | ~ |
| A structured model of one life that grows over time | ✓ | ✕ | ~ | ~ | ✕ |
| Speaks as the author, not a neutral assistant | ✓ | ✕ | ✓ | ✓ | ✓ |
| In the book: ask the author about the exact line | ✓ | ~ | ✕ | ✕ | ✓ |
| Private reader memory, erasable on demand | ✓ | ✕ | ~ | ✓ | ✕ |
| Owned by the author, no platform in the middle | ✓ | ✕ | ✕ | ✕ | ✕ |
| Safety built into the architecture | ✓ | ✕ | ✕ | ✕ | ✕ |
The advantage is the assembly, not the parts
Comparable products are hosted platforms that hold the data and run the model for the customer. This system runs the entire stack: its own embedder, its own index, its own keys, on first-party infrastructure, with no platform in the middle. Most persona products use flat retrieval and let the base model improvise. This one builds a structured life-model and refuses to invent. Those two postures rarely appear together, and almost never on infrastructure a single author owns end to end. As of mid-2026, to the author's knowledge no widely available product yet combines all four: owned outright, a structured life-model, hard grounding, and survivor-safe design. The parts are industry standard. The integration is not.
A book you can immerse yourself in like never before
For five thousand years, stories have run one way. The author writes, the reader reads, and the conversation ends there, usually with everything the author knew leaving when they do.
Artificial intelligence changes that, though not the way most people feared. The future of storytelling is not books written by AI. It is books that can answer back.
Picture reading a memoir, stopping at the one sentence that stays with you, and instead of only wondering what came before it or underneath it, you ask. The story opens. The context, the memory, the author's later understanding, all of it becomes part of the reading. Not a replacement for the book. An expansion of it.
Bill's aim reaches further still. Where a reader can today ask the author a question, the work is heading toward something closer to walking through the story itself, moving inside its rooms and its years rather than watching them from the outside. This is not a feature bolted onto an old form. It is the early shape of a participatory medium, a book the reader does not simply finish but enters, one that opens onto the moments behind the pages and lets a person stand where the writing once stood. None of that asks the system to invent a single thing, because every step the reader takes will be paved with what the author actually wrote.
We happen to be alive at the moment a book is becoming something it has never been: not only a story to read, but one you can explore alongside the authors.

Join the inner circle.
Release dates and news first, the story behind the story, and the things that actually helped me climb out, plus what this community keeps passing around. Straight to your inbox, only when there is something worth your time. No noise, no selling.
No spam, ever. Unsubscribe anytime.